

NVIDIA Grace Hopper Superchip


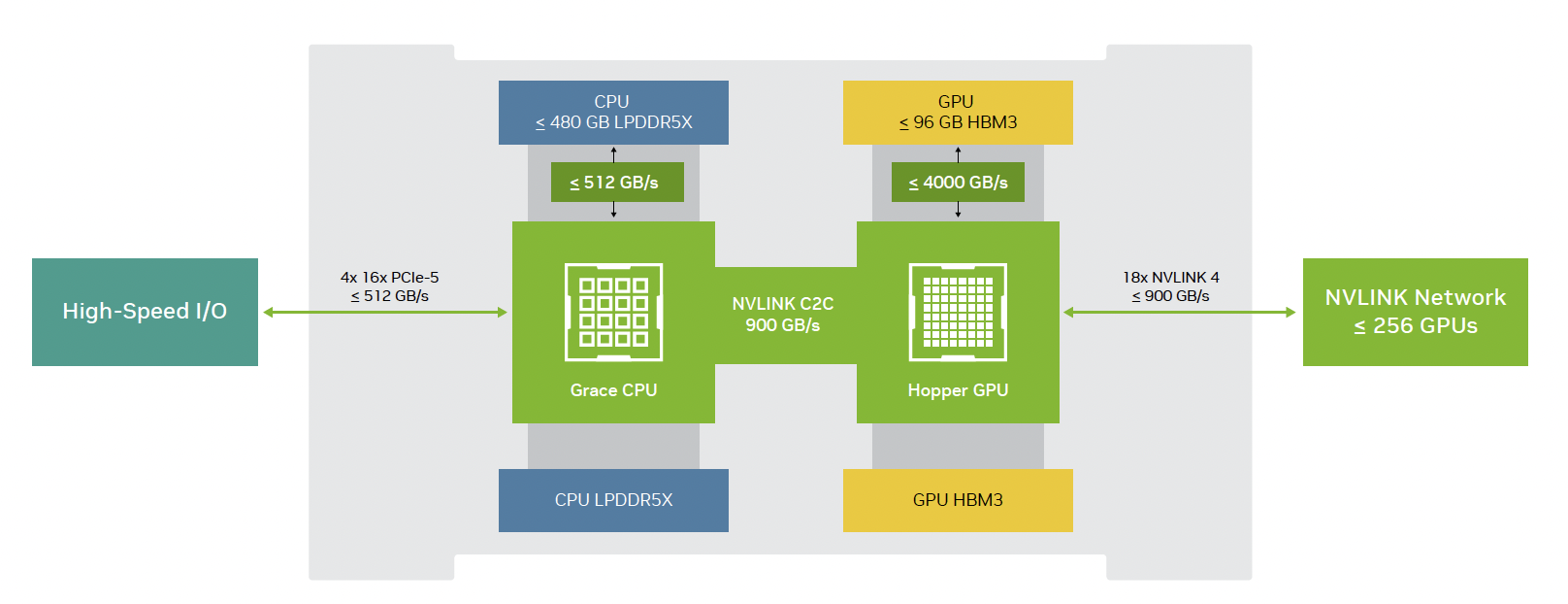
The NVIDIA Grace™ Hopper™ architecture brings together the groundbreaking performance of the NVIDIA Hopper GPU with the versatility of the NVIDIA Grace CPU in a single super chip, connected with the high-bandwidth, memory-coherent NVIDIA® NVLink® Chip-2-Chip (C2C) interconnect.
NVIDIA NVLink-C2C is a memory-coherent, high-bandwidth, and low-latency interconnect for Superchips. The heart of the Grace Hopper Superchip, it delivers up to 900 gigabytes per second (GB/s) of total bandwidth, which is 7X higher than PCIe Gen5 lanes commonly used in accelerated systems. NVLink-C2C enables applications to oversubscribe the GPU’s memory and directly utilize NVIDIA Grace CPU’s memory at high bandwidth. With up to 480GB of LPDDR5X CPU memory per Grace Hopper Superchip, the GPU has direct access to 7X more fast memory than HMB3. Combined with the NVIDIA NVLink Switch System, all GPU threads running on up to 256 NVLink-connected GPUs can access up to 150 terabytes (TB) of memory at high bandwidth.
Power and Efficiency With the Grace CPU
The NVIDIA Grace CPU delivers twice the performance per watt of conventional x86-64 platforms and is the world’s fastest Arm data center CPU. The Grace CPU was designed for high single-threaded performance, high-memory bandwidth, and outstanding data-movement capabilities. The NVIDIA Grace CPU combines 72 Neoverse V2 Armv9 cores with up to 480GB of server-class LPDDR5X memory with ECC. This design strikes the optimal balance of bandwidth, energy efficiency, capacity, and cost. Compared to an eight-channel DDR5 design, the Grace CPU LPDDR5X memory subsystem provides up to 53 percent more bandwidth at one-eighth the power per gigabyte per second.
Performance and Speed With the Hopper H100 GPU
The H100 is NVIDIA’s ninth-generation data center GPU, and it delivers an order-of-magnitude performance leap for large-scale AI and HPC over the prior-generation NVIDIA A100 Tensor Core GPU. The NVIDIA H100 GPU based on the new Hopper GPU architecture features multiple innovations:
> New fourth-generation Tensor Cores perform faster matrix computations than ever before on an even broader array of AI and HPC tasks.
> A new Transformer Engine enables H100 to deliver up to 9X faster AI training and up to 30X faster AI inference compared to the prior GPU generation.
> Secure Multi-Instance GPU (MIG) partitions the GPU into isolated, right-size instances to maximize quality of service (QoS) for smaller workloads.
The Power of Coherent Memory
NVLink-C2C memory coherency increases developer productivity, performance, and the amount of GPU-accessible memory. CPU and GPU threads can concurrently and transparently access both CPU and GPU resident memory, allowing developers to focus on algorithms instead of explicit memory management. Memory coherency lets developers only transfer the data they need and not migrate entire pages to and from the GPU. It also provides lightweight synchronization primitives across GPU and CPU threads by enabling native atomics from both the CPU and GPU. Fourth-generation NVLink allows accessing peer memory with direct loads, stores, and atomic operations, so accelerated applications can solve larger problems more easily than ever.
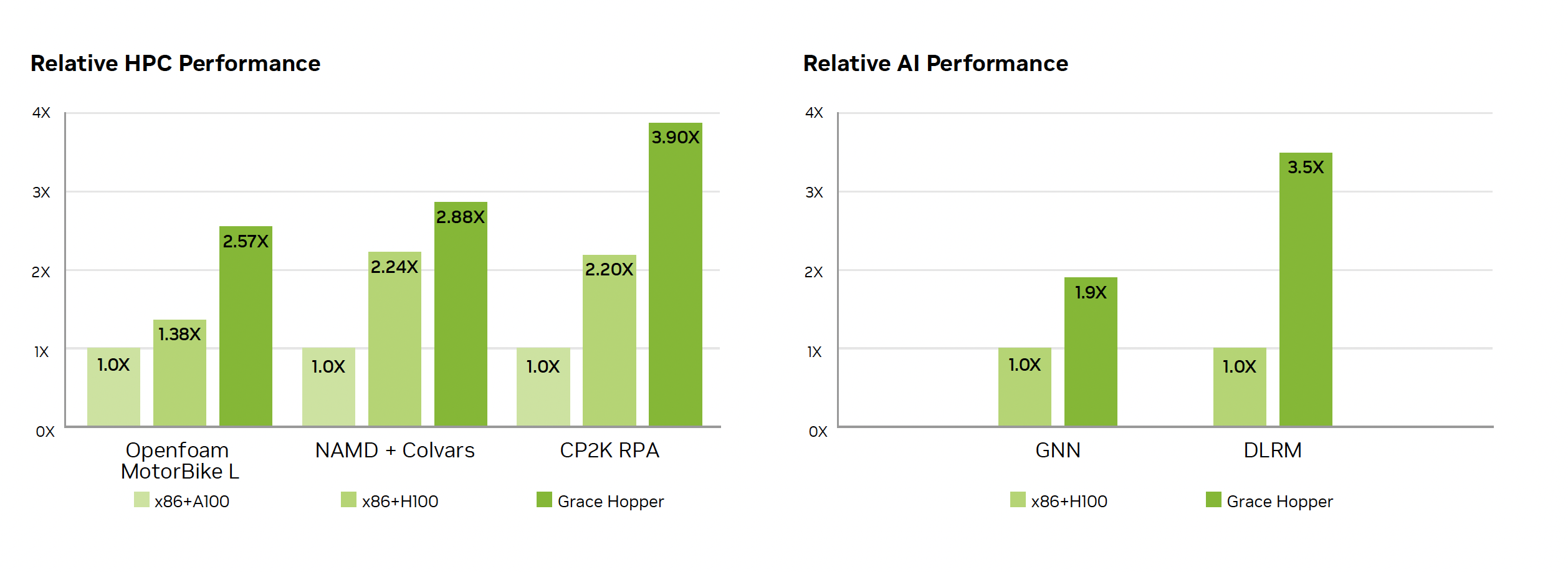
Class-Leading Performance for HPC and AI Workloads
The Grace Hopper Superchip is the first true heterogeneous accelerated platform for HPC and AI workloads. It accelerates any applications with the strengths of both GPUs and CPUs while providing the simplest and most productive heterogeneous programming model to date, enabling scientists and engineers to focus on solving the world’s most important problems. Together with NVIDIA networking technologies, NVIDIA Grace Hopper Superchips provide the recipe for the next generation of HPC supercomputers and AI factories, letting customers take on larger datasets, more complex models, and new workloads.
Full NVIDIA Platform Support
The NVIDIA Grace Hopper Superchip extends the existing large and diverse ecosystem of 64-bit Arm processors. The very same containers, application binaries, and operating systems that run on other Arm products run on Grace Hopper without modification—only faster. And for customers who wish to leverage and build upon NVIDIA’s software expertise, the NVIDIA Grace Hopper Superchip is supported by the full NVIDIA software stack, including the NVIDIA HPC, NVIDIA AI, and NVIDIA Omniverse™ platforms.
General Enquiry
NVIDIA Grace Hopper Superchip
The NVIDIA Grace™ Hopper™ architecture brings together the groundbreaking performance of the NVIDIA Hopper GPU with the versatility of the NVIDIA Grace CPU in a single super chip, connected with the high-bandwidth, memory-coherent NVIDIA® NVLink® Chip-2-Chip (C2C) interconnect.
NVIDIA NVLink-C2C is a memory-coherent, high-bandwidth, and low-latency interconnect for Superchips. The heart of the Grace Hopper Superchip, it delivers up to 900 gigabytes per second (GB/s) of total bandwidth, which is 7X higher than PCIe Gen5 lanes commonly used in accelerated systems. NVLink-C2C enables applications to oversubscribe the GPU’s memory and directly utilize NVIDIA Grace CPU’s memory at high bandwidth. With up to 480GB of LPDDR5X CPU memory per Grace Hopper Superchip, the GPU has direct access to 7X more fast memory than HMB3. Combined with the NVIDIA NVLink Switch System, all GPU threads running on up to 256 NVLink-connected GPUs can access up to 150 terabytes (TB) of memory at high bandwidth.
Power and Efficiency With the Grace CPU
The NVIDIA Grace CPU delivers twice the performance per watt of conventional x86-64 platforms and is the world’s fastest Arm data center CPU. The Grace CPU was designed for high single-threaded performance, high-memory bandwidth, and outstanding data-movement capabilities. The NVIDIA Grace CPU combines 72 Neoverse V2 Armv9 cores with up to 480GB of server-class LPDDR5X memory with ECC. This design strikes the optimal balance of bandwidth, energy efficiency, capacity, and cost. Compared to an eight-channel DDR5 design, the Grace CPU LPDDR5X memory subsystem provides up to 53 percent more bandwidth at one-eighth the power per gigabyte per second.
Performance and Speed With the Hopper H100 GPU
The H100 is NVIDIA’s ninth-generation data center GPU, and it delivers an order-of-magnitude performance leap for large-scale AI and HPC over the prior-generation NVIDIA A100 Tensor Core GPU. The NVIDIA H100 GPU based on the new Hopper GPU architecture features multiple innovations:
> New fourth-generation Tensor Cores perform faster matrix computations than ever before on an even broader array of AI and HPC tasks.
> A new Transformer Engine enables H100 to deliver up to 9X faster AI training and up to 30X faster AI inference compared to the prior GPU generation.
> Secure Multi-Instance GPU (MIG) partitions the GPU into isolated, right-size instances to maximize quality of service (QoS) for smaller workloads.
The Power of Coherent Memory
NVLink-C2C memory coherency increases developer productivity, performance, and the amount of GPU-accessible memory. CPU and GPU threads can concurrently and transparently access both CPU and GPU resident memory, allowing developers to focus on algorithms instead of explicit memory management. Memory coherency lets developers only transfer the data they need and not migrate entire pages to and from the GPU. It also provides lightweight synchronization primitives across GPU and CPU threads by enabling native atomics from both the CPU and GPU. Fourth-generation NVLink allows accessing peer memory with direct loads, stores, and atomic operations, so accelerated applications can solve larger problems more easily than ever.
Class-Leading Performance for HPC and AI Workloads
The Grace Hopper Superchip is the first true heterogeneous accelerated platform for HPC and AI workloads. It accelerates any applications with the strengths of both GPUs and CPUs while providing the simplest and most productive heterogeneous programming model to date, enabling scientists and engineers to focus on solving the world’s most important problems. Together with NVIDIA networking technologies, NVIDIA Grace Hopper Superchips provide the recipe for the next generation of HPC supercomputers and AI factories, letting customers take on larger datasets, more complex models, and new workloads.
Full NVIDIA Platform Support
The NVIDIA Grace Hopper Superchip extends the existing large and diverse ecosystem of 64-bit Arm processors. The very same containers, application binaries, and operating systems that run on other Arm products run on Grace Hopper without modification—only faster. And for customers who wish to leverage and build upon NVIDIA’s software expertise, the NVIDIA Grace Hopper Superchip is supported by the full NVIDIA software stack, including the NVIDIA HPC, NVIDIA AI, and NVIDIA Omniverse™ platforms.